Bike Dataset#
Bike is a dataset for regression from tabular inputs.
Please download and unzip the dataset here and update the tutorial data path accordingly.
It contains hourly rental data for bikes spanning two years. The goal is to predict the total count of bikes rented during each hour covered by the test set (test.csv), using only information available prior to the rental period (train.csv).
The following image summarizes the dataset.
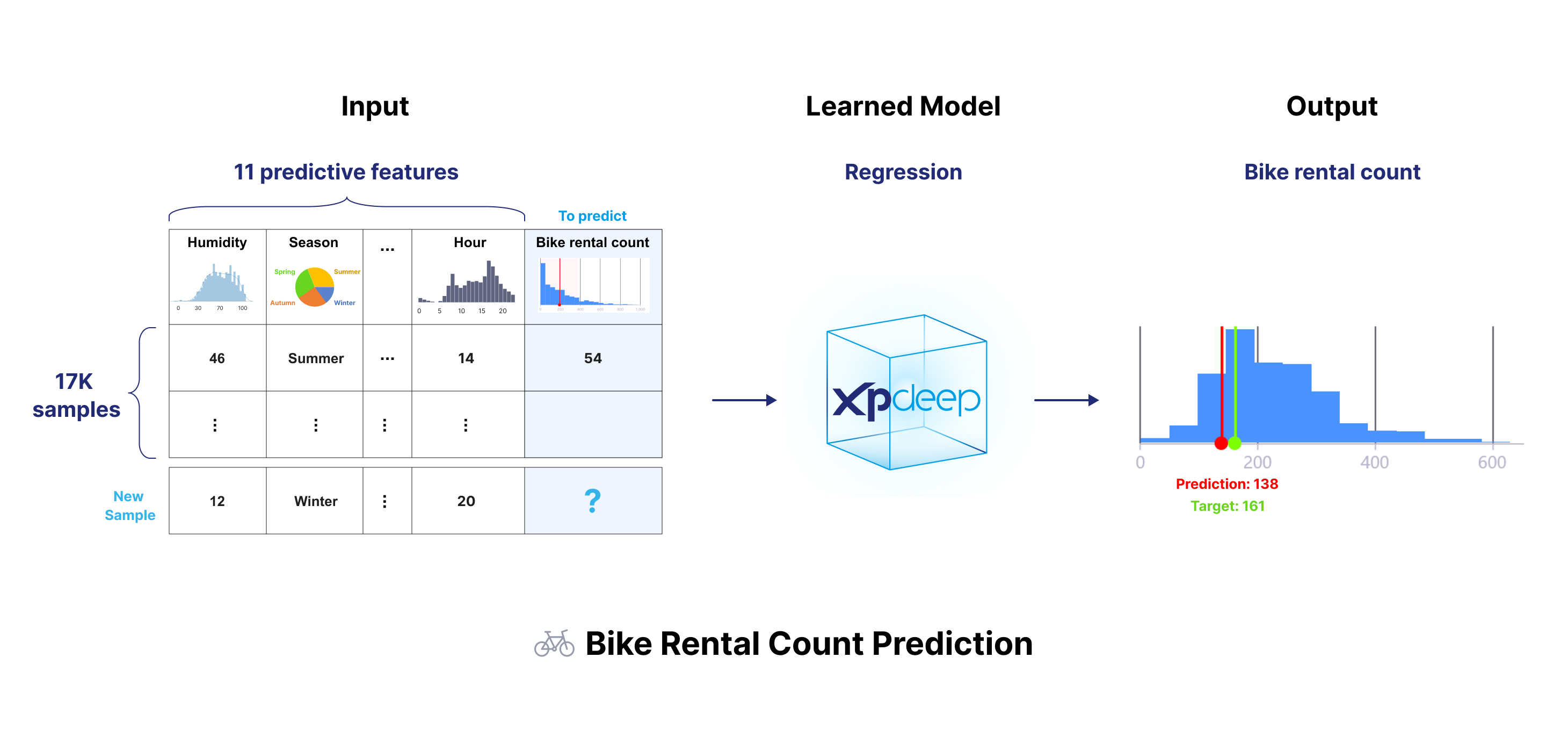
Please follow this end-to-end tutorial to prepare the dataset, create and train the model, and finally compute explanations.
Prepare the Dataset#
1. Split and Convert your Raw Data#
The first step consists in creating your train, test and validation splits as StandardDataset. As we only have a train
and test files, we will use 20% of the train split to create a validation split.
import pandas as pd
# Load the CSV file
test_data = pd.read_csv('test.csv')
train_val_data = pd.read_csv('train.csv')
Here we decide to drop three columns, "atemp", "casual" and "registered" (not present in the test file) as they won't help for the regression task.
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
In addition, we convert the column "datetime" to "year", month", "hour", "weekday" and "datetime".
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
The dataset is then split into train, test and validation set.
from sklearn.model_selection import train_test_split
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
In addition, we need to add an index_xp_deep column on each split, please see the doc.
train_data['index_xp_deep'] = range(len(train_data))
test_data['index_xp_deep'] = range(len(test_data))
val_data['index_xp_deep'] = range(len(val_data))
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
As stated in the doc, Xpdeep requires a ".parquet" file to create the dataset. The original data is stored as a ".csv" file, therefore each split must be converted to a ".parquet" file.
Tip
To get your ".parquet" files, you can easily convert each split from pandas.DataFrame to pyarrow.Table first.
Warning
Here with set preserve_index to False in order to remove the DataFrame "index" column from the resulting Pyarrow Table.
import pyarrow as pa
import pyarrow.parquet as pq
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
2. Upload your Converted Data#
Warning
Don't forget to set up a Project and initialize the API with your credentials !
from xpdeep import init, set_project
from xpdeep.project import Project
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId",name="Bike Tutorial"))
With your Project set up, you can upload the converted parquet files into Xpdeep server.
from xpdeep.dataset.upload import upload
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
3. Instantiate a Dataset#
Here we instantiate a ParquetDataset for the train set only. We will create the validation and test dataset later.
from xpdeep.dataset.parquet_dataset import ParquetDataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
4. Find a schema#
We use the AutoAnalyzer to get a schema proposal on the train set.
The only requirement is to specify the target name, here the "income" feature. It takes two values: "<=50K" and ">50K".
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
+------------------------------------------------+
| Schema Contents |
+--------------------+---------------+-----------+
| Type | Name | Is Target |
+--------------------+---------------+-----------+
| CategoricalFeature | season | ❌ |
| CategoricalFeature | holiday | ❌ |
| CategoricalFeature | workingday | ❌ |
| CategoricalFeature | weather | ❌ |
| NumericalFeature | temp | ❌ |
| NumericalFeature | humidity | ❌ |
| NumericalFeature | windspeed | ❌ |
| NumericalFeature | count | ✅ |
| CategoricalFeature | year | ❌ |
| CategoricalFeature | month | ❌ |
| CategoricalFeature | hour | ❌ |
| CategoricalFeature | weekday | ❌ |
| Metadata | index_xp_deep | |
+--------------------+---------------+-----------+
Note
Please note that the index_xp_deep column is automatically recognized and stored as a Metadata in the Schema.
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
5. Fit the schema#
With your Schema analyzed on the train set, you can now fit the schema to fit each feature preprocessor on the train set.
We use the same FittedSchema to create a FittedParquetDataset corresponding to the validation and test set.
from xpdeep.dataset.parquet_dataset import FittedParquetDataset
fit_test_dataset = FittedParquetDataset(split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema)
fit_val_dataset = FittedParquetDataset(split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
And that's all for the dataset preparation. We now have three FittedParquetDataset, each with its FittedSchema,
ready to be used.
Prepare the Model#
We need now to create an explainable model XpdeepModel.
1. Create the required torch models#
We have a regression task with tabular input data. We will use a basic Multi Layer Perceptron (MLP) for this task.
Tip
Model input and output sizes (including the batch dimension) can be easily retrieved from the fitted schema.
Therefore:
- The
FeatureExtractionModelwill embed input data into a 57 dimension space. - The
TaskLearnerModelwill return an output of size 1. - No
BackboneModelis required for this simple task.
import torch
from xpdeep.model.zoo.mlp import MLP
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
2. Explainable Model Specifications#
Here comes the crucial part: we need to specify model specifications under ModelDecisionGraphParameters
to get the best explanations (Model Decision Graph and Inference Graph).
from xpdeep.model.model_builder import ModelDecisionGraphParameters
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
For further details, see docs
Note
All parameters have a default value, you can start by using those default value, then iterate and update the configuration to find suitable explanations.
3. Create the Explainable Model#
Given the model architecture and configuration, we can finally instantiate the explainable model XpdeepModel.
from xpdeep.model.xpdeep_model import XpdeepModel
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
Train#
The train step is straightforward: we need to specify the Trainer parameters.
from functools import partial
import torch
from xpdeep.metrics.metric import DictMetrics, TorchLeafMetric, TorchGlobalMetric
from torchmetrics import MeanSquaredError
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
Note
We use TorchGlobalMetric and TorchLeafMetric to encapsulate the metrics. They give us more flexibility, for instance
here we compute metrics on the raw data and not on the preprocessed data, as it easier to interprete an MSE on
the un-normalized bike count.
Find more information here.
We can now train the model:
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
The training logs are displayed in the console:
Epoch 1/20 - Loss: 0.980: 1%|▏ | 1/69 [00:00<00:33, 2.04it/s]
Epoch 1/20 - Loss: 1.052: 3%|▎ | 2/69 [00:00<00:26, 2.56it/s]
Epoch 1/20 - Loss: 1.165: 4%|▍ | 3/69 [00:01<00:23, 2.77it/s]
Epoch 1/20 - Loss: 1.131: 6%|▌ | 4/69 [00:01<00:21, 3.00it/s]
Once the model trained, it can be used to get explanations.
Explain#
Similarly to the Trainer, explanations are computed with an Explainer interface.
1. Build the Explainer#
We provide the Explainer quality metrics to get insights on the explanation quality. In addition, we compute
along with the explanations histograms to get a detailed distribution on targets, predictions and errors. Finally, we set description_representativeness
to 1000.
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
Tip
Here we reuse metrics from the train stage for convenience, but they can be adapted to your needs !
2. Model Functioning Explanations#
Model Functioning Explanations are computed with the global_explain method.
model_explanations = explainer.global_explain(trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
We can visualize explanations with XpViz, using the link in model_explanations.visualisation_link, if you already
have requested the correct credentials.
3. Inference and their Causal Explanations#
We need a subset of samples to compute Causal Explanations on. Here we filter the test set on two features, selecting samples with "temp" under 30 from the "year" 2011 only. It represents 2461 samples.
from xpdeep.filtering.filter import Filter
from xpdeep.filtering.criteria import NumericalCriterion, CategoricalCriterion
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
Explanation can then be computed using the local_explain method from the Explainer.
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
👀 Full file preview
"""Bike workflow, regression, tabular data."""
from functools import partial
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import torch
from sklearn.model_selection import train_test_split
from torchmetrics import MeanSquaredError
from xpdeep import init, set_project
from xpdeep.dataset.parquet_dataset import FittedParquetDataset, ParquetDataset
from xpdeep.dataset.upload import upload
from xpdeep.explain.explainer import Explainer
from xpdeep.explain.quality_metrics import Infidelity, Sensitivity
from xpdeep.explain.statistic import DictStats, HistogramStat, VarianceStat
from xpdeep.filtering.criteria import CategoricalCriterion, NumericalCriterion
from xpdeep.filtering.filter import Filter
from xpdeep.metrics.metric import DictMetrics, TorchGlobalMetric, TorchLeafMetric
from xpdeep.model.model_builder import ModelDecisionGraphParameters
from xpdeep.model.xpdeep_model import XpdeepModel
from xpdeep.model.zoo.mlp import MLP
from xpdeep.project import Project
from xpdeep.trainer.callbacks import EarlyStopping
from xpdeep.trainer.trainer import Trainer
torch.random.manual_seed(5)
# ##### Prepare the Dataset #######
# 1. Split and Convert your Raw Data
# Load the CSV file
test_data = pd.read_csv("test.csv")
train_val_data = pd.read_csv("train.csv")
test_data = test_data.drop(columns=["atemp"])
train_val_data = train_val_data.drop(columns=["casual", "atemp", "registered"])
for dataset in [test_data, train_val_data]:
dataset["datetime"] = pd.to_datetime(dataset["datetime"])
dataset["year"] = dataset["datetime"].dt.year
dataset["month"] = dataset["datetime"].dt.month
dataset["hour"] = dataset["datetime"].dt.hour
dataset["weekday"] = dataset["datetime"].dt.weekday
dataset.drop(columns=["datetime"], inplace=True)
# Split the data into training and validation sets
train_data, val_data = train_test_split(train_val_data, test_size=0.2, random_state=42)
train_data["index_xp_deep"] = range(len(train_data))
test_data["index_xp_deep"] = range(len(test_data))
val_data["index_xp_deep"] = range(len(val_data))
# Convert to pyarrow Table format
train_table = pa.Table.from_pandas(train_data, preserve_index=False)
val_table = pa.Table.from_pandas(val_data, preserve_index=False)
test_table = pa.Table.from_pandas(test_data, preserve_index=False)
# Save each split as ".parquet" file
pq.write_table(train_table, "train.parquet")
pq.write_table(val_table, "val.parquet")
pq.write_table(test_table, "test.parquet")
# 2. Upload your Converted Data
init(api_key="api_key", api_url="api_url")
set_project(Project(id="BikeId", name="Bike Tutorial"))
directory = upload(
directory_name="bike_uploaded",
train_set_path="train.parquet",
test_set_path="test.parquet",
val_set_path="val.parquet",
)
# 3. Instantiate a Dataset
train_dataset = ParquetDataset(
split_name="train",
identifier_name="my_local_dataset",
path=directory["train_set_path"],
)
# 4. Find a schema
analyzed_train_dataset = train_dataset.analyze(target_names=["count"])
print(analyzed_train_dataset.analyzed_schema)
# 5. Fit the schema
fit_train_dataset = analyzed_train_dataset.fit()
fit_test_dataset = FittedParquetDataset(
split_name="test",
identifier_name="my_local_dataset",
path=directory["test_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
fit_val_dataset = FittedParquetDataset(
split_name="val",
identifier_name="my_local_dataset",
path=directory["val_set_path"],
fitted_schema=fit_train_dataset.fitted_schema,
)
# ##### Prepare the Model #######
# 1. Create the required torch models
input_size = fit_train_dataset.fitted_schema.input_size[1]
target_size = fit_train_dataset.fitted_schema.target_size[1]
print(f"input_size: {input_size} - target_size: {target_size}")
feature_extraction = MLP(input_size=input_size, hidden_channels=[128, 30], activation_layer=torch.nn.ReLU)
task_learner = MLP(input_size=30, hidden_channels=[target_size], activation_layer=torch.nn.ReLU)
# 2. Explainable Model Specifications
model_specifications = ModelDecisionGraphParameters(
graph_depth=3,
discrimination_weight=0.1,
target_homogeneity_weight=0.1,
target_homogeneity_pruning_threshold=0.1,
population_pruning_threshold=0.2,
balancing_weight=0.0,
prune_step=10,
)
# 3. Create the Explainable Model
xpdeep_model = XpdeepModel.from_torch(
fitted_schema=fit_train_dataset.fitted_schema,
feature_extraction=feature_extraction,
task_learner=task_learner,
backbone=None,
decision_graph_parameters=model_specifications,
)
# ##### Train #######
# Metrics to monitor the training.
metrics = DictMetrics(
mse=TorchGlobalMetric(metric=partial(MeanSquaredError), on_raw_data=True),
leaf_metric_mse=TorchLeafMetric(metric=partial(MeanSquaredError), on_raw_data=True),
)
callbacks = [EarlyStopping(monitoring_metric="Total loss", mode="minimize")]
# Optimizer is a partial object as pytorch needs to give the model as optimizer parameter.
optimizer = partial(torch.optim.AdamW, lr=0.001)
trainer = Trainer(
loss=torch.nn.MSELoss(reduction="none"),
optimizer=optimizer,
callbacks=callbacks,
start_epoch=0,
max_epochs=20,
metrics=metrics,
)
trained_model = trainer.train(
model=xpdeep_model,
train_set=fit_train_dataset,
validation_set=fit_val_dataset,
batch_size=128,
)
# ##### Explain #######
# 1. Build the Explainer
statistics = DictStats(
histogram_target=HistogramStat(on="target", num_bins=20, num_items=1000, on_raw_data=True),
histogram_prediction=HistogramStat(on="prediction", num_bins=20, num_items=1000, on_raw_data=True),
histogram_error=HistogramStat(on="prediction_error", num_bins=20, num_items=1000, on_raw_data=True),
variance_target=VarianceStat(on="target", on_raw_data=True),
variance_prediction=VarianceStat(on="prediction", on_raw_data=True),
)
quality_metrics = [Sensitivity(), Infidelity()]
explainer = Explainer(
description_representativeness=1000, quality_metrics=quality_metrics, metrics=metrics, statistics=statistics
)
# 2. Model Functioning Explanations
model_explanations = explainer.global_explain(
trained_model,
train_set=fit_train_dataset,
test_set=fit_test_dataset,
validation_set=fit_val_dataset,
)
visualisation_link = model_explanations.visualisation_link
# 3. Inference and their Causal Explanations
my_filter = Filter("testing_filter", fit_test_dataset)
my_filter.add_criteria(
NumericalCriterion(fit_test_dataset.fitted_schema["temp"], max_=30),
CategoricalCriterion(fit_test_dataset.fitted_schema["year"], categories=[2011]),
)
causal_explanations = explainer.local_explain(trained_model, fit_test_dataset, my_filter)
visualisation_link = causal_explanations.visualisation_link
We can again visualize causal explanations using the visualisation_link.